Blog...
A blog post is loading...
Jan 1, 2025
Loading…
A blog post is loading...
Jan 1, 2025
Loading…
SWE-Lancer is a much needed improvement to SOTA coding benchmarks. It rewards agentic iteration, rather than static correctness of code. Setting RL loose on the benchmark will dramatically improve AI coding performance.
Feb 18, 2025
SWE-Lancer is a much needed improvement to SOTA coding benchmarks. Unlike SWE-Bench, which evaluates models on GitHub issues with associated pull requests, SWE-Lancer shifts the focus to freelance engineering work, pulling from 1,488 Upwork tasks worth $1M in real payouts.
Below are my notes, but you can check out the full paper if you care on arXiv.
Overall my take is that this is much more usable as a real world benchmark. It rewards agentic iteration, rather than static correctness of code -- meaning the code will work in our projects vs. just work. Also: Setting RL loose on the benchmark will dramatically improve AI coding performance.






SWE-lancer Benchmark. Can an AI model achieve $1m in revenue through SWE-Tasks? Makes you remember what OpenAI’s definition of AGI is: $100b in profit. Interesting coincidence, isn’t it
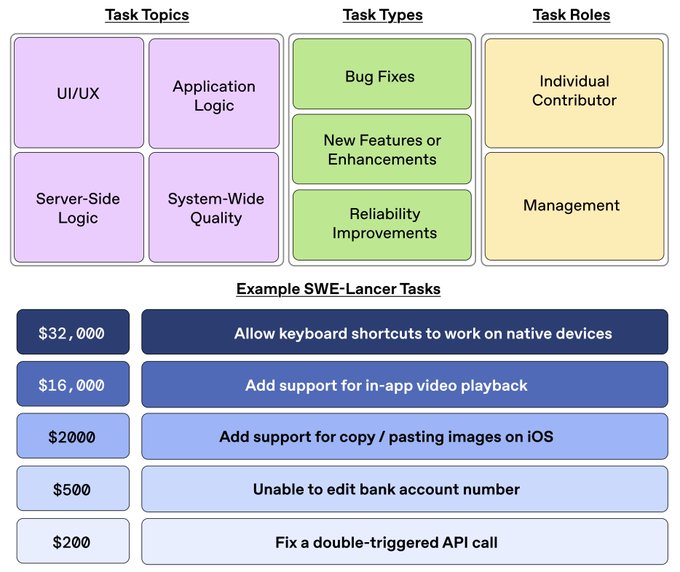
Today we’re launching SWE-Lancer—a new, more realistic benchmark to evaluate the coding performance of AI models. SWE-Lancer includes over 1,400 freelance software engineering tasks from Upwork, valued at $1 million USD total in real-world payouts. openai.com/index/swe-lanc…