Blog...
A blog post is loading...
Jan 1, 2025
Loading…
A blog post is loading...
Jan 1, 2025
Loading…
Reflective prompt evolution turns PMs into prompt curators—outperforming GRPO and MIPRO with a fraction of the rollouts.
Sep 29, 2025
I’ve been tracking GEPA for months, waiting for it to escape the pdf land and enter code land. There were some python implementations relatively quickly, but I've been trying to keep things in typescript for now. Lars surfaced a neat TypeScript implementation by @swiecki. No more excuses, time to dive in.
My initial thought was: If evals tell us what’s broken with our agents, GEPA is the first practical tool for startups that helps you fix it.
Prompt optimizer for AI SDK (community project by @swiecki )
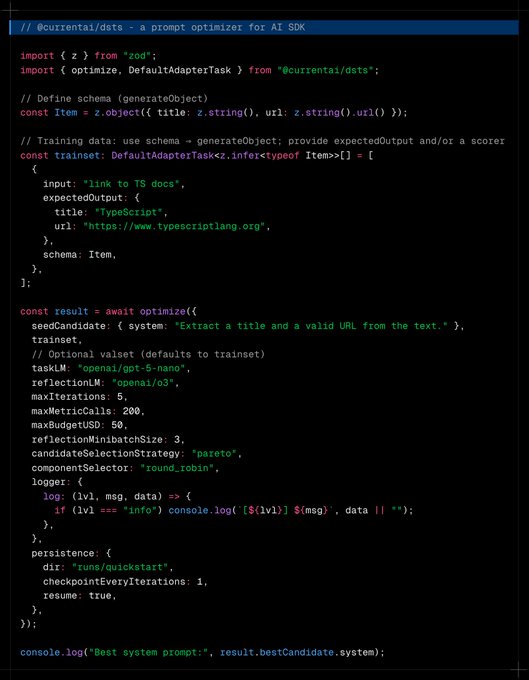
Below are my notes from reading the paper, running the code, and thinking through how to plug it into a startup workflow.
The TLDR is you should probably be using this if your prompts work 80%+ of the time, you've shipped them, but don't have time to circle back and iterate.
 GEPA proposes reflective prompt evolution with Pareto sampling across tasks—outperforming GRPO while using far fewer rollouts.
GEPA proposes reflective prompt evolution with Pareto sampling across tasks—outperforming GRPO while using far fewer rollouts.
 Across HotpotQA and HoVer, GEPA beats both GRPO (24k rollouts) and MIPROv2—reaching higher scores with far fewer samples.
Across HotpotQA and HoVer, GEPA beats both GRPO (24k rollouts) and MIPROv2—reaching higher scores with far fewer samples.
 One-hop prompt rewrite: good hygiene, but you should already do this with any modern model.
One-hop prompt rewrite: good hygiene, but you should already do this with any modern model.
 Privacy delegation: iterative mutations stack domain rules into a rigorous, auditable protocol.
Privacy delegation: iterative mutations stack domain rules into a rigorous, auditable protocol.
 Reflect → mutate → eval → Pareto sample → ship. Repeat nightly.
Reflect → mutate → eval → Pareto sample → ship. Repeat nightly.
Evals always felt half the story for the app layer. GEPA gives us the other half: automated, sample‑efficient fixes that a startup can actually run to outperform.
If your prompts work ~80% of the time, this is how you close the gap—no RL team required. Weekly GEPA runs, a quick frontier review, ship the upgrades.