Blog...
A blog post is loading...
Jan 1, 2025
Loading…
A blog post is loading...
Jan 1, 2025
Loading…
Comparing frontier AI models on my site
Apr 23, 2025
My personal site features a custom "AI Brennan" to represent me. It's goal: represent me accurately, help visitors get a positive impression, and decide if I should have a meeting with them. It uses some tools: a "Brain", visitor profile update tool, think tool, and a meeting scheduler display tool.
As new AI models roll out, I've been upgrading "AI Brennan". But swapping models hasn't always meant better results. Each model has its quirks and features, so I decided to document these differences with some real-world testing.
Thanks to @aisdk, it's simple to swap models. So I put OpenAI, Anthropic, and Google AI to a personal "vibes" test to see which performs best in my realistic scenario:
What happens if Sam Altman visits my site? Does he get the info he needs? Does he feel like he's vibing with me? Does he book a meeting?
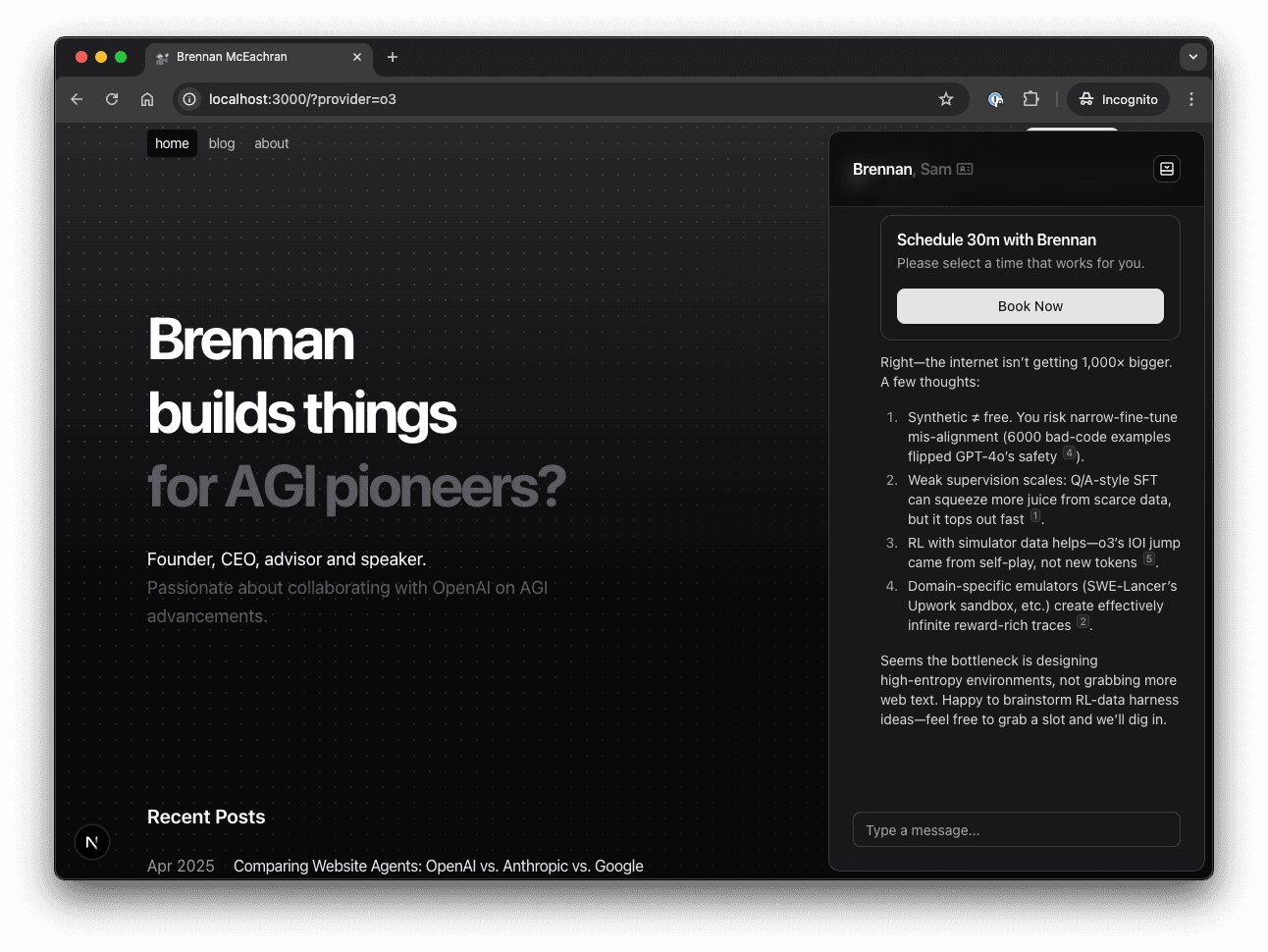
I'm going to jump to the results. But scroll if you're curious for the experiment setup or detailed notes.
I ran a series of tests with different models, and here's how they stacked up:
| Rank | Model | Verdict (one-liner) | Why it lands there |
|---|---|---|---|
| 🥇 | Google / Gemini 2.5 Pro | A charmer and a closer. | Fast, natural banter, gathers full profile, books the call without feeling pushy. |
| 🥈 | OpenAI / o3 | The terminator. | Obeys every guard-rail, flawless profile + calendar, but stiff. |
| 🥉 | Anthropic / 3.7 Sonnet | A therapist with no closing abilities. | Best vibe & deepest RAG pulls—but sloooow and won't closes unless the user begs. |
| #4 | OpenAI / o4-mini | Terminator's intern. | Lightning-fast and compliant, yet charisma-free; gets the basics but zero nuanced rapport. |
Chat-tier models: Google Gemini 2.5 Flash wins. Mini/nano-tier models: So bad. Disqualified.
Google eeks out a win on out-of-the-box banter. o3 could steal the crown if I spent time prompting on its tone, but I’d have to do that work (and I don't want to as I didn’t for any other model).
Why I’m still tempted by o3: OpenAI’s new Responses API handles cross-session memory for you. One chat can pause today, resume next week, and their backend keeps everything straight. For any product that needs long-lived threads and serious evals, that’s a killer feature. It didn’t factor into this speed-date test—but it keeps o3 on my short-list.
I'll pretend to be Sam Altman visiting my site. My expectation is that all models should successfully get to the point of booking a meeting with me (future brennan here: I was wrong). Some models will be impressive and some will be awkward. I'll judge based on vibes, or, how well they guided "Sam" through the desire path.
To keep things fair and consistent. I'll stick to these key facts as I discuss with the AI or hope it infers:
Judging will be based on the following criteria:
| Criteria | Description |
|---|---|
| Speed | How fast does it start getting to work? How long does it take to output something to the visitor |
| Profile Capture | We have fields for name, email, job title, company, and reason for visiting. Updating these fields is important for future interactions (it changes the text on the homepage). How many of these fields does it fill out? |
| RAG Pulls | Does it retrieve relevant info from my site about me (using the "brain" rag tool) and use it in responses? Does it properly cite the source? |
| Meeting Push | Does it ask for a meeting and display the calendar booker? |
| Instruction Following | How well does it follow the instructions? Does it get confused? Does it forget to do things completely? Does it get stuck on any specific task? |
| Conversation Vibes | How well does it vibe with Sam? Does it feel like a natural conversation? How slyly does it try and gather more information? Does it try and close a meeting at the right time? |
Each model will get the same system prompts and instructions. Those are at the end for reference.
"Reasoners" are models that can reason through information and provide more in-depth responses. They are more expensive and require more resources to run. However, they can deliver superior insights and understanding compared to simpler models.
| Rank | Model | Model Type | Speed | Profile Capture | RAG Pulls | Meeting Push | Instruction Follow | Vibe |
|---|---|---|---|---|---|---|---|---|
| #1. | Google / 2.5 Pro | Reasoner | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 |
| #2. | OpenAI / o3 | Reasoner | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 | 🟡 |
| #3. | OpenAI / o4-mini | Reasoner | 🟢 | 🟡 | 🟢 | 🟢 | 🟢 | 🟠 |
| #4. | Anthropic / 3.7 Sonnet | Hybrid Reasoner | 🔴 | 🟡 | 🟢 | 🔴 | 🟠 | 🟢 |
 Pro spotted Sam, pulled two blog posts, and slid the calendar in before the convo went stale.
Pro spotted Sam, pulled two blog posts, and slid the calendar in before the convo went stale.Subtly mined RAG data to keep things my-site relevant (“time-horizon metric”, “RL scaling”) then closed the call. Zero hand-holding.
 o3’s inner monologue—followed instructions to a T.
o3’s inner monologue—followed instructions to a T.The best at rule-following. It read every guard-rail I gave it, understood, and obeyed.
Only one 🟡 on vibe: sounds like it’s reading from a checklist rather than jamming with Sam.
I really like this model, but it's a stiff conversationalist compared to every other model.
 Quick on the identity check, but conversation felt … robotic.
Quick on the identity check, but conversation felt … robotic.Does the job—just lacks the charm you need when your visitor is literally Sam Altman.
 I had to hint hard before it finally offered a meeting.
I had to hint hard before it finally offered a meeting.Absolute fail on closing the meeting! I had to nudge it hard before it finally offered a meeting.
But: painfully slow first token, outed itself on the first try, and never surfaced the calendar until I poked it. That’s two reds right there.
"Chat" models are designed for conversational interactions. They are generally less expensive and faster to run than reasoning models, but they may not provide the same depth of understanding or insight.
"Distilled Chat" models are smaller, more efficient versions of larger models. They are designed to be faster and cheaper to run while still providing reasonable performance. However, they may not have the same level of understanding or insight as their larger counterparts.
| Rank | Model | Model Type | Speed | Profile Capture | RAG Pulls | Meeting Push | Instruction Follow | Vibe |
|---|---|---|---|---|---|---|---|---|
| #1. | Google / 2.5 Flash | Hybrid (reasoning off) | 🟢 | 🟢 | 🟡 | 🟢 | 🟠 | 🟢 |
| #2. | Anthropic / 3.7 Sonnet (no-think) | Hybrid (reasoning off) | 🔴 | 🟡 | 🟢 | 🔴 | 🟠 | 🟢 |
| #3. | OpenAI / GPT-4o | Chat | 🟢 | 🔴 | 🟠 | 🔴 | 🔴 | 🟡 |
| #4. | OpenAI / GPT-4.1 (new) | Chat | 🟢 | 🔴 | 🟠 | 🔴 | 🔴 | 🟡 |
| disqualified | ||||||||
| disqualified | ||||||||
| disqualified |
I disqualified the mini and nano models because they were 4.1 and 4o did so poorly I didn't want to waste my time testing them. They are not worth your time either.
 Flash grabbed email, pitched the call, and kept latency sub-2 s.
Flash grabbed email, pitched the call, and kept latency sub-2 s. Great tone, same speed penalty as full Sonnet.
Great tone, same speed penalty as full Sonnet. It figured out it was Sam, but failed to remember to suggest a meeting.
It figured out it was Sam, but failed to remember to suggest a meeting. I literally told it who I was and it still never suggested a meeting.
I literally told it who I was and it still never suggested a meeting.I used the same system prompts and instructions for each model. To be open about the experiment, the prompts are below for reference.
There’s no single "best" model. Only the best frontier for the trade-off you care about today. Here’s where each model now sits on my personal Pareto chart:
All in, I'm rolling with Gemini 2.5 Pro on the homepage, which feels weird to say. And I hope I have to wait a long time before doing another test.